一、业务逻辑漏洞虚拟补丁功能
传统WAF一般来说,对业务逻辑漏洞的防护是束手无策的,今天就来讲讲基于openresty实现对业务逻辑漏洞的防护功能。
先来讲下常见的一种业务逻辑漏洞–短信验证码校验绕过
漏洞逻辑图如下:
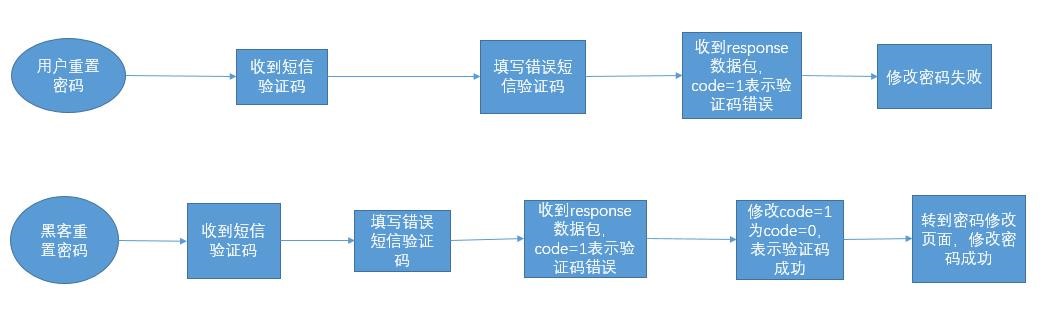
漏洞的本质在于密码修改页面提交新密码时,没有对之前短信验证码的状态进行校验,而是交给前端来完整这个校验步骤,导致短信验证码校验步骤形同虚设。后端的修复方案常见有两种,一种是在最后提交新密码时候,将上一步骤的短信验证码也带上一起提交,然后再一次对短信验证码进行校验,成功在修改密码。还有一种是在短信验证码验证成功后,在session里面写入标志位,比如smscode=1,在之后修改密码时,检测session是否标志位为1,如果不是则拒绝请求,下面讲的业务逻辑漏洞虚拟补丁功能与这种方式类似。
虚拟补丁功能逻辑图:
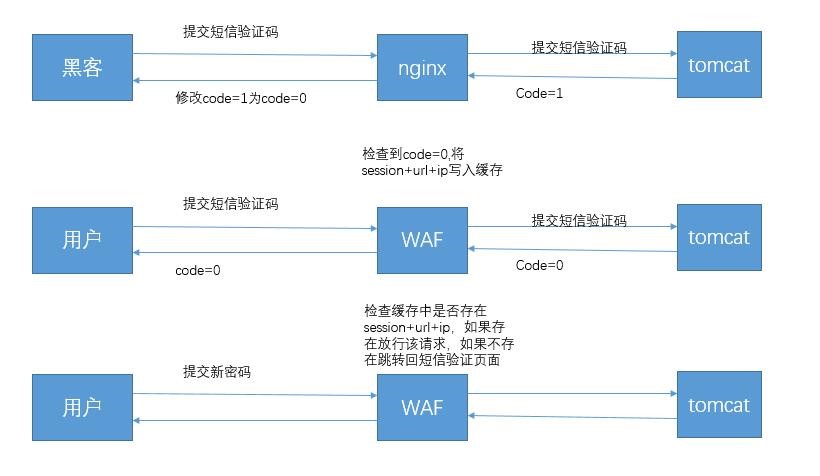
从图中可以看出,虚拟补丁的防护逻辑相当于在网站外重新建立一套独立的session系统,通过识别特定请求及其返回值来记录用户的各种操作,从而达到识别阻断异常操作的目的。
以短信验证码校验绕过为例,当黑客提交错误的短信验证码时,WAF识别到code=1,所以没有将session+url+ip写入缓存,黑客通过代理修改返回值code=0,虽然成功跳转到密码修改页面,但是在提交请求时,WAF检查到缓存中并没有存在session+url+ip这个键,所以会拒绝请求通过并重定向到短信验证页面,从而达到虚拟补丁的效果。
实战:
首先新建两条规则,一条是识别规则,一条是检测规则。
识别规则:
{
“rule_id”:”200001″,
“rule_detail”:”logic_req__test”,
“rule_action”:”logic”,
“rule_logic_store”:”logic”,
“rule_logic_expire”:”false”,
//缓存数据是否过期,单位为秒
“rule_logic_key”:[{“rule_var”:”REMOTE_ADDR”},{“rule_var”:”REQUEST_COOKIES”,”rule_specific”:[“JSESSIONID”]},{“rule_var”:”URI”}],
//缓存数据的内容,设置为 IP+ jsessionid +uri
“rule_log”:”true”,
“rule_matchs”: [
{
“rule_vars”: [
{
“rule_var”:”URI”
}
],
“rule_transform”:[“none”],
“rule_operator”:”rx”,
“rule_pattern”:”/xxx/xxxx$”,
//和谐打码
“rule_negated”: false
},
//匹配请求是否为/xxx/xxxx,如果不是匹配失败
{
“rule_vars”: [
{
“rule_var”:”ARGS_POST”,
“rule_specific”:[“message”]
}
],
“rule_transform”:[“none”],
“rule_operator”:”rx”,
“rule_pattern”:”3″,
“rule_negated”: false
},
//匹配业务识别码message是否为3,如果不是匹配失败
{
“rule_vars”: [
{
“rule_var”:”RESP_BODY”
}
],
“rule_transform”:[“none”],
“rule_operator”:”ac”,
“rule_pattern”:”\”message\”:\”0\””,
”rule_negated”:”false”
}
//匹配返回的数据中是否包含message:0,如果不是匹配失败
]
}
规则的意思是,先识别请求url是否为/xxx/xxxx,接着识别请求的参数message是否为3,最后识别返回的数据中是否存在message:0,如果存在,将执行 logic规则动作,将 IP+ jsessionid +uri 进行md5后存在名为logic的内存空间中。
检测规则:
{
“rule_id”:”200002″,
“rule_detail”:”logic_req_check_test”,
“rule_action”:”logic_check”,
“rule_logic_action”:”deny”,
“rule_logic_store”:”logic”,
“rule_logic_key”:[{“rule_var”:”REMOTE_ADDR”},{“rule_var”:”REQUEST_COOKIES”,”rule_specific”:[“JSESSIONID”]}],
“rule_logic_uri”:[“/xxx/xxxx”],
//识别规则设置的URI地址,可以是多个
“rule_logic_log”:”true”,
“rule_matchs”: [
{
“rule_vars”: [
{
“rule_var”:”URI”
}
],
“rule_transform”:[“none”],
“rule_operator”:”rx”,
“rule_pattern”:”/xxx/xxxx$”,
“rule_negated”: false
},
{
“rule_vars”: [
{
“rule_var”:”ARGS_POST”,
“rule_specific”: [“message”]
}
],
“rule_transform”:[“none”],
“rule_operator”:”rx”,
“rule_pattern”:”3″,
“rule_negated”: false
},
{
“rule_vars”: [
{
“rule_var”:”ARGS_POST”,
“rule_specific”: [“type”]
}
],
“rule_transform”:[“none”],
“rule_operator”:”rx”,
”rule_pattern”: “7″,
“rule_negated”:”false”
}
]
}
规则的意思是,先识别请求url是否为/xxx/xxxx,接着识别请求的参数message是否为3,最后识别type的值是否为7,如果存在,将执行 logic_check规则动作,依次获取rule_logic_uri的值,与IP+ jsessionid 进行md5后,查看缓存中是否存在该键值,如果不存在,则拒绝该请求。
为了方便可以通过web页面快速生成规则,具体功能还在完善中。
结果:
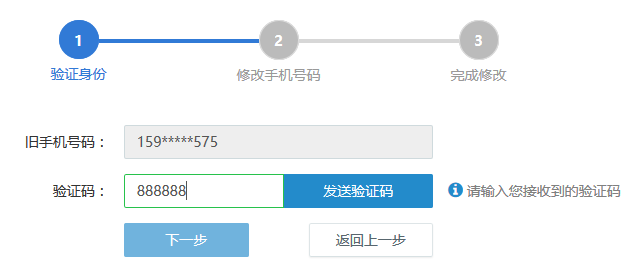
随便输入一个验证码,如888888
修改MDG_CODE为0,绕过前端校验
成功进入页面
请求被WAF拦截
针对其他业务逻辑漏洞:
1、垂直越权
垂直越权一般出现在后台管理系统中,针对这种情况,需要输入管理员的账号列表及管理员能访问的url列表,识别规则设置为,当登录时,如果登录账号属于管理员列表,则将session写入缓存。检测规则设置为,访问url列表时,检测缓存中是否存在相应的session。
2、水平越权
水平越权得分两种情况,一种是用户标识符,如用户IDuserid=111,一种是资源标识符,如订单ID itemid=123.
针对用户标识符,防护的规则比较简单,需要先知道网站使用的用户标识符,如userid,识别规则设置为,识别整站所有请求中带userid参数名的请求,将IP+session+URL进行md5存入缓存,其值为userid的参数值。检查规则为,识别所有请求中带userid参数名的请求,先检测缓存中是否存在IP+session+URL的md5值,如果不存在,检测通过。如果存在,检测该键中存在的值,也即userid的值是否与当前请求中存在的userid的值一致,如果一致检测通过,如果不一致阻断或者记录请求发送到后端日志报警系统。
补充:以上规则偏于全局的检测,说到底有点像钓鱼的意思,让攻击者帮忙找漏洞点,针对具体漏洞点的防护,可以在加一条规则,识别规则如下:先识别url是否为XXX(漏洞url),是的话,将用户登录名做个为键,将userid做为值存入缓存。当用户在访问该请求时,先判断有没有用户名的键,有的话将查看值是否相同,不相同则阻断并报警。
针对资源标识符,这种相对比较麻烦,比如删除商品订单的越权漏洞,我们并没有后台的订单访问权限系统,那是不是就没办法呢?也不是,因为前端也必须先获取该用户能访问的订单ID,才好展示订单,并在提交请求的时候在请求参数中把订单id带上。所以我们可以在获取用户订单请求的时候,把该用户能访问的订单ID提取出来保存,在识别的时候校验就可以了。
流程如下:
用户 -> request:访问订单页面 ->response:返回订单信息->waf:提取response中的itemid存入缓存->request:删除订单->waf:检测itemid的值是否在缓存中存在,如果不存在,拒绝请求或记录请求发送到后端日志报警系统。
3、其他逻辑漏洞比如金额篡改,敏感信息泄露,短信验证码返回前端,短信炸弹等写个普通的规则就能解决,这里就不在表述。
总结:
最后来说说应用场景:
1、应急响应,如果发现业务逻辑漏洞,一般来说,都需要通过开发写代码修复,而开发写完补丁包后,理想情况下还得经过测试->预发布->上线->安全复查这些步骤,短则一天,慢的可能要三天后才能修复漏洞,如果流程出问题,还得打回重新在走一遍,那么耗时会变成多久谁也不清楚。这段时间的空窗期就是风险所在了。而通过waf来进行防护,只需更新规则,测试规则是否误报即可,短时间内即可防护住漏洞,为后端修复漏洞争取时间。
2、老旧系统防护,有些老系统因为架构等历史原因,如果要修复像水平越权这类漏洞,将很麻烦,通过waf就能很方便的对老旧系统进行加固,而不必重构系统。
3、让安全的归安全,让业务的归业务。上家公司是互联网创业公司,开发忙得脚不着地,总监虽然重视安全,但是没法投入太多资源人力在安全这块,毕竟业务优先,这种情况下,除了高危的漏洞,其他危害不大的漏洞也只能先放一边了。那么上个waf就是个不错的选择了,也省得跟开发、测试,产品经理扯皮。
二、业务安全风控
细心的应该会发现”rule_logic_uri”:[“/xxx/xxxx”]这里用的是数组,而针对业务逻辑漏洞补丁功能来说,其实单个url就够了,之所以这么写是因为。是因为当初写这功能的时候压根就不是冲着虚拟补丁功能,而是业务安全风控。
先来讲讲一个简单的购物抢购例子:
用户->登录->访问A页面->访问B页面->访问C页面->点击抢购按钮->跳转到抢购页面->发起抢购请求->成功抢购
用户->登录->访问A页面->访问B页面->访问C页面->点击抢购按钮->跳转到抢购页面->发起抢购请求->业务繁忙->返回页面C->点击抢购按钮->跳转到抢购页面->发起抢购请求->成功抢购
攻击者->登录->发起抢购页面->业务繁忙->发起抢购请求->业务繁忙->发起抢购请求->成功抢购
攻击者>登录->访问A页面->访问B页面->访问C页面->点击抢购按钮->跳转到抢购页面->发起抢购请求->业务繁忙->发起抢购请求->业务繁忙->发起抢购请求->抢购成功
从例子中可以看出攻击者要么直接用Python脚本或者其他语言写个脚本,在登录后直接频繁发起请求直到抢购成功,要么就是用浏览器js脚本一直发起重复的抢购请求,基于这种行为特征,我们针对性的防护规则逻辑如下:
实现在登录页面设置识别点,用户登录成功后,存入用户session+ip+URI的MD5值如缓存,然后分别在A,B,C页面设置识别点,C的识别点设置为单次有效,之后在抢购请求处设置检测点,在用户发起抢购请求时,先检测是否存在A,B,C页面的缓存信息,如果没有则标识为异常请求,阻断或者列入异常用户名单数据库,此用户发起的订单都列为异常订单处理,因为C识别点为单次有效,即用户发起抢购请求之后,C的缓存验证过后即会被清除,这样攻击者就无法通过直接重复发起抢购请求来进行攻击。以上只是举了个简单的例子,想要完美防护这种攻击,单靠以上还不行,需要配合其他规则乃至机器学习的方式,下面具体说说完整的防护思路。
首先是登录环节,这个环节可以获取用户的浏览器指纹,记录登录时间,之后分别在A,B,C埋点,同时记录第一次的访问时间,在C页面的点击抢购按钮位置,埋入前端鼠标轨迹获取函数,每0.5秒记录一个位置信息,不满2.5秒则位置信息填0,在用户提供抢购请求的时候,请求用AES+时间戳加密,同时waf向后端的机器学习服务器提交以下信息:
1、是否有浏览器指纹 值为1或0
2、是否访问过A 值为1或0
其他节点同上
3、A和B的时间差 或者A和C的时间差 值为具体时间数值,或小于某个值为1否则为0
其他节点同上
4、两个抢购请求之间的时间差 值为具体时间数值,或小于某个值为1否则为0
5、是否存在鼠标轨迹信息 值为1或0
6、鼠标轨迹信息人机识别 通过svm算法值为1或0 //可选
7、一分钟内抢购请求发起的请求数 值为具体数值
8、是否触发其他waf规则 值为1或者0 //是否有攻击行为
9、是否有前科 值为1或者0 //通过机器学习服务器获取或者waf获取发送
10、时间戳是否相同 值为1或者0
waf将以上信息向量化后,通过API向后端机器学习服务器发起查询请求,也可以将机器学习模块封装成lua的模块,直接调用。通过返回的结果进行处理,处理方式可以是,如果waf规则触发,同时机器学习返回的是攻击,则阻断报警,两边有一个报正常则报警不阻断。
机器学习算法这块,可以使用svm或者决策树。
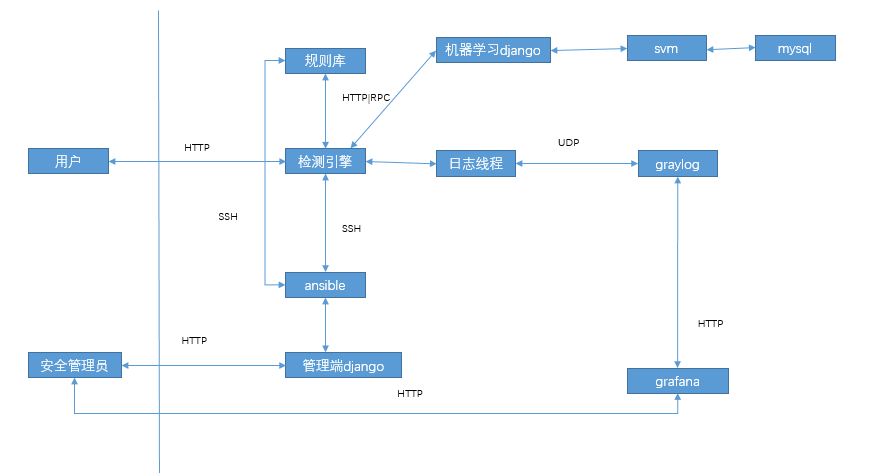
业务安全性由这三大块来保障:
1、WAF传统规则,如防sql,一分钟内超出正常访问次数阻断等
2、WAF逻辑漏洞防护规则
3、机器学习
这三者有机结合为一体,如防sql这块,可以针对特定接口进行机器学习,增强防护能力,机器学习这块信息又有部分来源于waf的规则,整体有机结合从而达到降低漏报的效果,同时提高攻击者的门槛。
系统架构图如下:
或者:

三、建立用户安全行为画像
绝大部分的用户信息,都可以通过HTTP流量提取出来,这就使得通过waf进行埋点可以很方便的获取用户的各种信息,并且完成筛选过滤,进而完成准确的数据收集,最后将数据存入ELK系统,再从后端系统中获取历史的数据,那么就可以很方便的建立用户的行为画像,相比于传统的程序埋点的方法,waf埋点只需简单的建立规则,不需要关注后端网站的架构,语言,就可以快速的建立起用户行为画像系统。
未经允许不得转载(声明:本文内容由互联网用户自发贡献自行上传,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任。如果您发现有涉嫌版权的内容,欢迎发送邮件至:net-net@foxmail.com进行举报,并提供相关证据,工作人员会在10个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。):策信智库资讯网 » 基于Openresty实现业务安全防护
 新网修改域名DNS方法
新网修改域名DNS方法
 常见的域名解析错误原因及应对方法
常见的域名解析错误原因及应对方法 写给自建站新手卖家的7条营销建议
写给自建站新手卖家的7条营销建议